[Reader Disclosure]Our content is reader-supported. This means we may earn a commission if you click on some of our links.
You ask an AI model a tricky problem, and it gives out a wrong answer with total confidence. Sound familiar? The gap between what LLMs can do and what we need them to do becomes obvious fast when complexity shows up.
Simple prompts work fine for basic tasks. But throw in multi-step reasoning, logic puzzles, or anything that needs actual thinking? That’s where AI starts tweaking.
Chain of Thought prompting changes this. It’s the technique that turns your AI from a quick-answer machine into something that actually shows its work, and gets better results because of it.
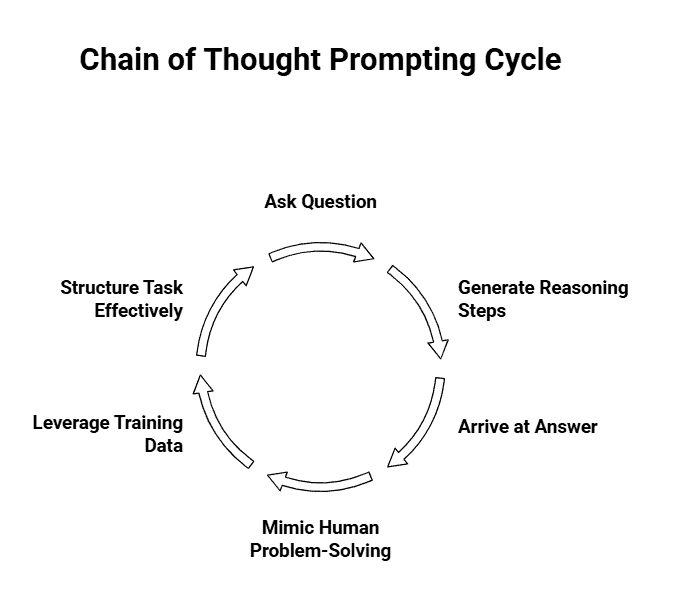
Chain of Thought prompting is a technique that gets LLMs to break down complex problems into clear, step-by-step reasoning. Instead of jumping straight to an answer, the model walks through intermediate steps, kind of like how you’d solve a problem on paper.
Think of it this way. You wouldn’t solve “What’s 15% of 340, minus 12, divided by 3?” in your head all at once. You’d break it down. First, 15% of 340. Then subtract 12. Then divide. CoT prompting teaches AI models to do the same thing, tackle complex problems by showing their work.
It emerged as a breakthrough because it makes AI reasoning transparent. You can see where the model went right or wrong. Plus, it taps into what LLMs already do well: generating fluent, logical text. CoT just adds structure to that strength.
How Does Chain of Thought Prompting Work?
Here’s the thing. Standard prompting asks a question and expects an answer. CoT prompting asks the question, then nudges the model to generate intermediate reasoning steps before landing on the final answer.
Let’s say you prompt: “A store had 23 apples. They sold 8 in the morning and 6 in the afternoon. How many are left?”
Without CoT, the model might just output “9” (and sometimes get it wrong). With CoT, it generates something like: “Start with 23 apples. Sold 8 in the morning: 23 – 8 = 15. Sold 6 in the afternoon: 15 – 6 = 9. Answer: 9 apples left.”
The model mimics human problem-solving. It plans the approach, breaks down the problem, and solves each piece sequentially. What makes this work is that LLMs are trained on tons of text that includes logical reasoning, explanations, tutorials, worked examples. CoT taps into that training by asking the model to generate that same kind of step-by-step text.
You’re not teaching it new skills. You’re structuring the task so it uses what it already knows more effectively. That’s why it works across math problems, logic puzzles, commonsense reasoning, and more.
Types of Chain of Thought Prompting
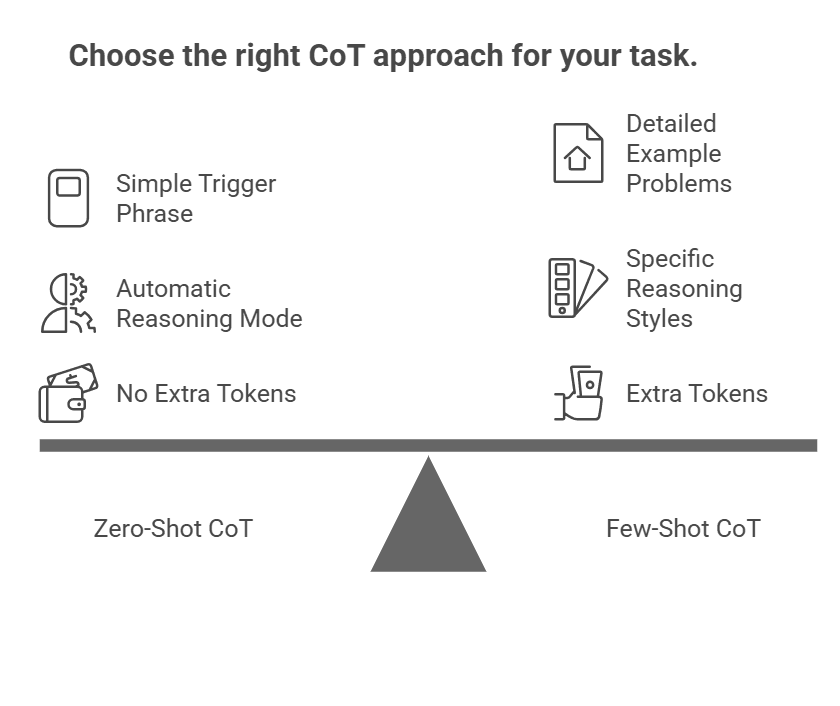
Here’s where things get practical. There are two main ways to use CoT prompting, and they differ in how much setup you need to do. One approach is quick and simple, just add a trigger phrase. The other requires a bit more work upfront but gives you more control over how the model reasons through problems.
Zero-Shot Chain of Thought Prompting
This is the easier path. You don’t need examples or elaborate setup. Just add a simple trigger phrase to your prompt, something like “Let’s think step by step” or “Let’s break this down”, and the model automatically shifts into reasoning mode.
Here’s what that looks like in practice:
Prompt: “If a train travels 120 miles in 2 hours, then speeds up and travels 180 miles in the next 2 hours, what’s its average speed for the entire trip? Let’s think step by step.”
The phrase at the end triggers the model to show its work instead of jumping straight to an answer. What’s interesting is that recent research on zero-shot CoT shows modern LLMs like Qwen2.5 handle this approach surprisingly well. You’re essentially asking the model to reason without showing it how, and it works because these models already learned logical patterns during training.
The appeal here is simplicity. No crafting examples, no extra tokens, just a straightforward addition to your prompt.
Few-Shot Chain of Thought Prompting
This approach takes more setup but gives you steering power. You include example problems with complete step-by-step solutions before asking your actual question. The examples show the model exactly what reasoning format you want.
Here’s the structure:
Example 1: “Problem: 15 + 27
Solution: First, I’ll add the ones place: 5 + 7 = 12. Write down 2, carry 1. Then add the tens place: 1 + 2 + 1 = 4. Answer: 42″
Example 2: [Another similar problem with steps]
Your question: “Problem: 38 + 56”
The model follows the pattern you established. This works well when you need specific reasoning styles, like showing financial calculations in a particular format or following domain-specific logic in medical or legal contexts. The examples act as a template.
You’d lean toward this when your task has nuances that a simple trigger phrase might miss.
Zero-Shot vs Few-Shot Chain of Thought
So which one should you actually use? That’s where recent findings get interesting.
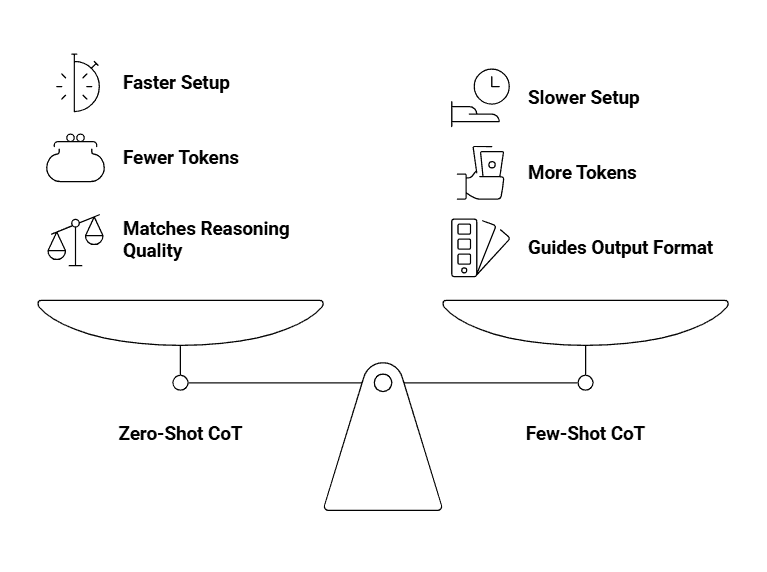
Zero-shot is faster to set up and uses fewer tokens. Few-shot requires crafting examples but theoretically guides the model better. But here’s the thing: Modern, capable models, zero-shot often match few-shot performance. The examples in few-shot prompts mainly help with output formatting rather than improving the actual reasoning quality.
What this means for you: start with zero-shot. Add that “Let’s think step by step” phrase and see how the model performs. It’s simpler, cheaper (fewer tokens), and works well for most reasoning tasks.
Switch to few-shot when you need one of these:
A specific output format (like showing calculations in a particular structure)
The examples aren’t teaching the model to reason, they’re teaching it how you want that reasoning presented. That’s the real difference. For pure problem-solving ability, modern LLMs already have strong reasoning capabilities built in. You’re just choosing whether to activate them with a simple phrase or guide their expression with examples.
How To Use Chain of Thought Prompting
Knowing how CoT works is one thing. Actually using it? That’s where the practical stuff matters. Let’s walk through the process so you can start getting better reasoning from your AI models today.
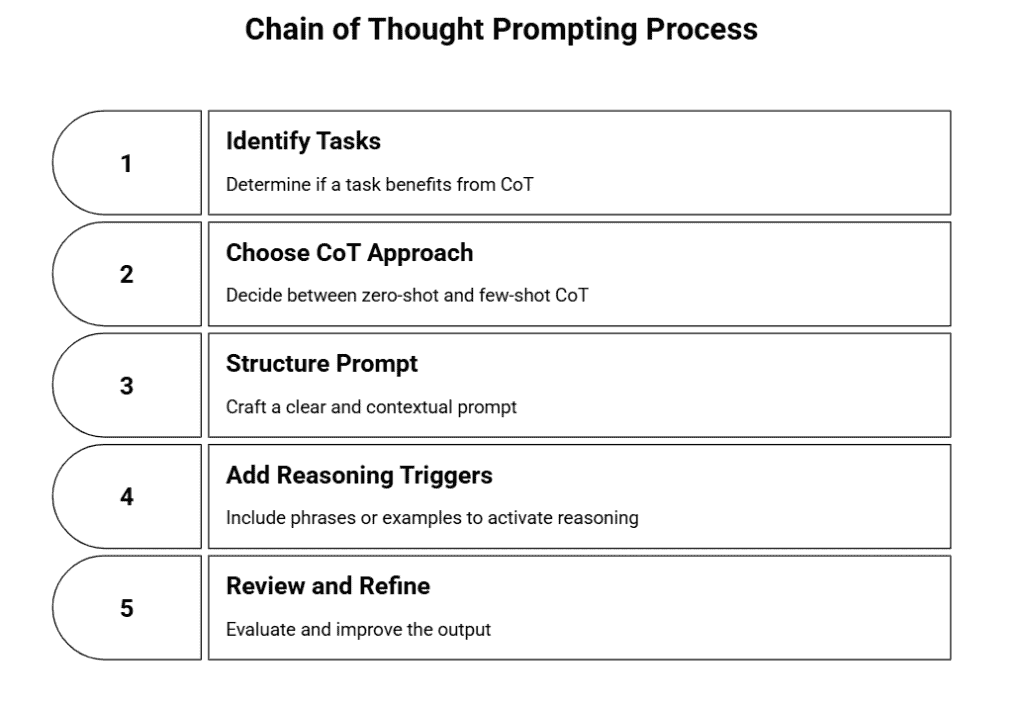
Step 1: Identify Tasks That Benefit from CoT
CoT works best for complex reasoning tasks, math problems, logic puzzles, multi-step analysis, or anything requiring careful thinking. If the task involves calculations, requires breaking down information, or needs you to consider multiple factors, CoT probably helps.
Simple factual questions don’t need it. “What’s the capital of France?” doesn’t benefit from step-by-step reasoning. But “If a train leaves Paris at 2 PM travelling 80 km/h…” absolutely does.
Quick test: Would you need to think through steps yourself to solve it? If yes, use CoT. If it’s a straight lookup or one-step answer, skip it.
Step 2: Choose Your CoT Approach
You’ve got two options: zero-shot or few-shot. Default to zero-shot for most situations. It’s simpler, faster to set up, and as we covered earlier, modern models handle it well.
Switch to few-shot when you need specific formatting or when your problem type is unusual. Maybe you want the reasoning displayed in a particular way, or you’re working with a domain that needs extra guidance.
Keep token costs in mind. Few-shot uses more tokens because you’re including multiple worked examples. If you’re processing hundreds of prompts, that adds up. Zero-shot keeps things lean.
Step 3: Structure Your Prompt
Start with a clear problem statement. Spell out exactly what you’re asking. Vague questions get vague reasoning.
Add context if it matters. Constraints, requirements, and specific formats include anything the model needs to know. If you’re solving a budget problem, mention the budget limit upfront.
Here’s what good structure looks like: “A store has 48 apples. They sell 15 in the morning and 22 in the afternoon. How many apples remain? Show your reasoning step by step.”
The problem is clear. The context is there. The trigger phrase sits at the end, ready to activate the reasoning process. That’s the formula.
Step 4: Add Reasoning Triggers or Examples
For zero-shot, add phrases like “Let’s think step by step” or “Show your reasoning” at the end of your prompt. “Let’s break this down” works too. These phrases signal to the model that you want intermediate steps, not just a final answer.
For few-shot, include 2-3 worked examples that match your problem type. If you’re doing geometry, show geometry examples with complete reasoning. Consistency matters, use the same format across all examples so the model picks up the pattern.
Place your trigger at the end of your prompt. It’s the last thing the model sees before generating, which makes it more effective at shaping the response.
Step 5: Review and Refine the Output
Check if the reasoning actually makes sense. Does each step logically follow from the last? Does the final answer match the logic shown?
Look for gaps or jumps. If the model suddenly skips from step 2 to step 5, something’s missing. If the math doesn’t add up or the logic feels off, your prompt needs work.
This is iterative. Your first attempt might not nail it. Adjust your problem statement to be clearer. Try different trigger phrases. If you’re using few-shot, swap in better examples. The output tells you what needs tweaking.
Chain of Thought Prompting Examples
Let’s see how this actually works with real prompts and responses.
Example 1: Math Problem Solving
Problem: A bakery sells cupcakes for $3 each. If they sold 45 cupcakes in the morning and 38 in the afternoon, but had to throw away 7 that didn’t sell, how much money did they make?
Prompt: “Solve this step by step: A bakery sells cupcakes for $3 each. If they sold 45 cupcakes in the morning and 38 in the afternoon, but had to throw away 7 that didn’t sell, how much money did they make?”
Model Response:
“Let me work through this:
1. Morning sales: 45 cupcakes
2. Afternoon sales: 38 cupcakes
3. Total cupcakes sold: 45 + 38 = 83 cupcakes
4. Note: The 7 thrown away don’t count since they weren’t sold
5. Revenue: 83 × $3 = $249
The bakery made $249.”
The trigger phrase “step by step” pushed the model to separate each calculation instead of jumping to the answer. That extra step where it noted the thrown-away cupcakes don’t count? That’s the kind of clarification that prevents mistakes.
Example 2: Logical Reasoning
Problem: All marine biologists study ocean life. Dr. Chen is a marine biologist. Does Dr. Chen study plants?
Prompt: “Let’s think this through carefully: All marine biologists study ocean life. Dr. Chen is a marine biologist. Does Dr. Chen study plants?”
Model Response:
“Let me reason through this:
1. Given: All marine biologists study ocean life
2. Given: Dr. Chen is a marine biologist
3. Therefore: Dr. Chen studies ocean life
4. Ocean life includes both plants (like seaweed, kelp) and animals
5. So yes, Dr. Chen likely studies plants—specifically marine plants that are part of ocean life.”
This shows how CoT catches subtle details. Without breaking down the logic, a model might say “no” because it separates “ocean life” from “plants” mentally. The step-by-step approach reveals the overlap.
Example 3: Multi-Step Analysis
Problem: Your team needs to launch a feature. Option A takes 2 weeks, costs $5,000, and reaches 10,000 users. Option B takes 4 weeks, costs $3,000, and reaches 25,000 users. You have a $4,000 budget and need to launch within 3 weeks. Which option should you choose?
Prompt: “Walk me through the decision process: [same problem details]”
Model Response:
“Let me evaluate each constraint:
1. Budget constraint: We have $4,000
– Option A: $5,000 (exceeds budget by $1,000)
– Option B: $3,000 (within budget)
2. Time constraint: Must launch within 3 weeks
– Option A: 2 weeks (within timeframe)
– Option B: 4 weeks (exceeds deadline by 1 week)
3. Neither option satisfies both constraints
4. Recommendation: Negotiate either more budget for A or extended timeline for B.”
This type of analysis benefits hugely from CoT because it forces the model to check each constraint separately. Without it, you might get an incomplete answer that only considers one factor.
When To Use Chain of Thought Prompting
CoT works best when you’re dealing with problems that need multiple thinking steps. Think math calculations, logical puzzles, planning tasks, or analysing data from different angles. If you’re asking an AI to calculate profit margins across five product lines, CoT will help. Same goes for tasks like “compare these three marketing strategies and recommend one based on cost, reach, and timing.”
Here’s when you should skip it: simple questions with direct answers. If you’re asking “What’s the capital of France?” or “Define photosynthesis,” CoT just adds unnecessary words. Also skip it when speed matters more than accuracy. You’re paying for more tokens and waiting longer for responses.
The quick rule? If a problem needs you to think through several steps on paper, use CoT. If you can answer it in one sentence without thinking, don’t.
Benefits of Chain of Thought Prompting
The biggest win is accuracy. Research shows CoT improves performance on complex reasoning tasks, especially with larger language models. You’re not just getting an answer you’re seeing how the AI arrived there.
That transparency matters. When you can read the reasoning steps, you catch errors before they become problems. If an AI calculates your quarterly revenue wrong, you’ll spot exactly where the math broke down.
CoT also handles multi-step problems way better than direct prompting. Planning a project with dependencies? Analysing if a business decision makes financial sense? The step-by-step format keeps everything organised.
Plus, when something goes wrong, you know where. Instead of a mysterious incorrect answer, you see “Step 3 used the wrong tax rate.” That makes fixing your prompts way easier.
Limitations of Chain of Thought Prompting
Let’s be honest about the downsides. CoT uses more tokens, which means higher costs and slower responses. If you’re running thousands of queries, that adds up fast.
The reasoning can still be wrong. Just because an AI shows its work doesn’t mean the work is correct. Recent research questions whether CoT reasoning represents true logical thinking or just sophisticated pattern matching based on training data. The AI might confidently walk through flawed logic.
For simple tasks, CoT creates unnecessary bloat. You’ll get three paragraphs explaining something that needed one sentence. That’s frustrating when you just want quick information.
And here’s the thing CoT doesn’t guarantee correctness. It increases accuracy on average, but you still need to check the reasoning yourself. Think of it as showing the AI’s work, not verifying it.
Best Practices for Chain of Thought Prompting
Start with zero-shot CoT. Add “Let’s think step by step” to your prompt and see what happens. If results aren’t great, then move to few-shot with examples. No need to overcomplicate things right away.
Write clear, specific problem statements. Vague questions get vague reasoning. Instead of “Should we expand?” try “Should we expand to the Denver market given our $200K budget, three competitors already there, and 18-month timeline?”
Test different trigger phrases. “Let’s work through this step by step” might work better than “Think carefully about this” for your specific use case. Structured approaches help you find what works consistently.
Review the reasoning steps, not just the final answer. That’s the whole point. If Step 2 makes a weird assumption, catch it there.
Keep your few-shot examples relevant. If you’re solving chemistry problems, don’t use economics examples. The AI learns from what you show it.
Balance detail with efficiency. You want enough steps to ensure accuracy, but not so many that you’re burning tokens on obvious transitions. If the AI explains that 2+2=4 in three sentences, your prompt needs tightening.
For large-scale applications, factor in token costs. CoT might not be worth it if you’re processing thousands of simple queries daily. Save it for the complex stuff that actually needs it.
A startup consultant, digital marketer, traveller, and philomath. Aashish has worked with over 20 startups and successfully helped them ideate, raise money, and succeed. When not working, he can be found hiking, camping, and stargazing.
Each week I share research backed AI oriented content in my newsletter.
There are AI ideas, AI trends, tutorials, and guides.
24k entrepreneurs read it. I'd love you to join.